One Playwright test, five services, three states
13 Apr 2026I run Shogunito — a multimedia project management app with a NestJS API, a React frontend, and MinIO for object storage. Five services in production. I used to monitor them with five separate health checks: ping, check for 200, done.
The problem wasn’t that they didn’t work. The problem was that they told me nothing useful. A 200 that takes 3 seconds is not the same as a 200 that takes 200ms. A storage outage doesn’t matter if the API already went down. And nobody noticed when an endpoint disappeared from the Swagger spec until a client called.
So I replaced them with a single MultiStep Check.
The check
import { test, expect } from '@playwright/test';
import {
getAPIResponseTime,
markCheckAsDegraded,
} from '@checkly/playwright-helpers';
const API = 'https://shogunitoapi.uliber.com';
const WEB = 'https://shogunitoweb.uliber.com';
const MINIO = 'https://shogunitominio.uliber.com/minio/health/live';
const SLOW = 800; // ms
test('Shogunito Infrastructure Health', async ({ request }) => {
await test.step('API core health', async () => {
const res = await request.get(`${API}/health`);
expect.soft(getAPIResponseTime(res), 'API slow').toBeLessThanOrEqual(SLOW);
expect(res).toBeOK();
const body = await res.json();
expect(body.data.status).toBe('ok');
});
await test.step('Auth service', async () => {
const res = await request.get(`${API}/api/v1/auth/health`);
expect.soft(getAPIResponseTime(res), 'Auth slow').toBeLessThanOrEqual(SLOW);
expect(res).toBeOK();
const body = await res.json();
expect(body.data.service).toBe('auth');
});
await test.step('OpenAPI spec', async () => {
const res = await request.get(`${API}/api/v1/docs-json`);
expect.soft(getAPIResponseTime(res), 'Docs slow').toBeLessThanOrEqual(SLOW);
expect(res).toBeOK();
const docs = await res.json();
expect(docs.paths['/api/v1/auth/login']).toBeTruthy();
expect(docs.paths['/api/v1/projects']).toBeTruthy();
expect(docs.paths['/api/v1/episodes']).toBeTruthy();
});
await test.step('Web UI', async () => {
const res = await request.get(WEB);
expect.soft(getAPIResponseTime(res), 'Web slow').toBeLessThanOrEqual(SLOW);
expect(res).toBeOK();
});
await test.step('MinIO storage', async () => {
const res = await request.get(MINIO);
expect.soft(getAPIResponseTime(res), 'MinIO slow').toBeLessThanOrEqual(SLOW);
expect(res).toBeOK();
});
if (test.info().errors.length) {
markCheckAsDegraded('Up but slow.');
}
});
That’s the whole thing. Five steps, sequential. Here’s why I made the decisions I made.
Why one chained test instead of five independent checks
If the API goes down, I don’t need four more alerts telling me the auth service, the docs, the frontend, and the storage are also unreachable. Five independent checks generate five incidents for one outage.
A sequential test gives me causality for free. If step 1 fails, the test stops — I know the root cause. If steps 1 through 3 pass but step 5 fails, I know the problem is isolated to MinIO. The order of the steps is the triage.
Why soft assertions
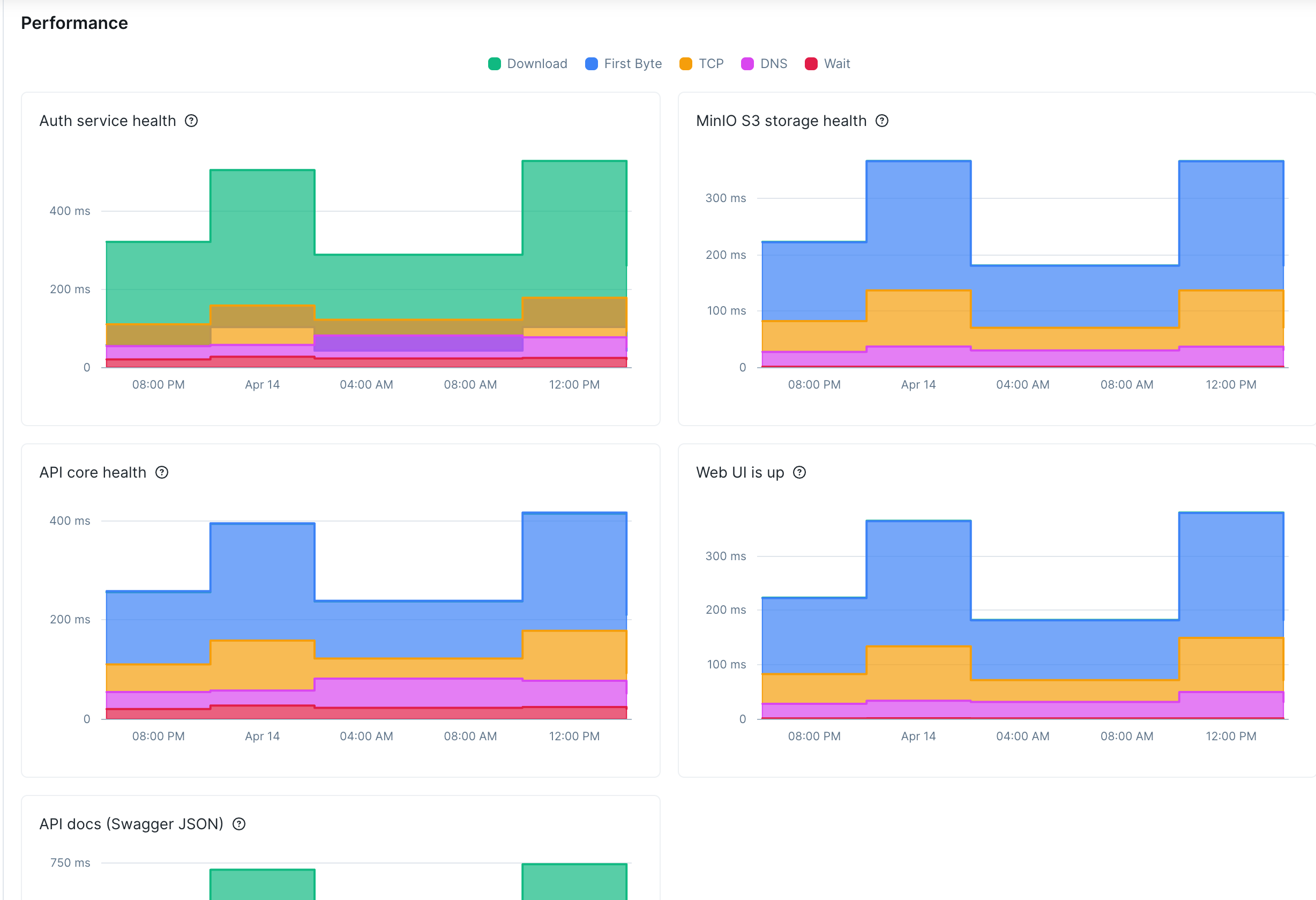
Every step has two kinds of assertions. The hard one (expect(res).toBeOK()) checks if the service is alive. The soft one (expect.soft(getAPIResponseTime(res)...) checks if it’s fast enough.
The difference: a hard assertion stops the test. A soft assertion logs the failure and keeps going.
This matters because when things degrade, they usually degrade unevenly. The API might respond in 100ms while MinIO takes 2 seconds. If I used hard assertions for everything, the test would stop at the first slow service and I’d never know about the rest. Soft assertions give me the full picture.
Why three states instead of two
Most monitoring is binary: up or down. But there’s a third state that matters more in practice — degraded. The service responds, but slowly. Nothing is broken. Yet.
markCheckAsDegraded() turns this into a first-class signal. Checkly shows it as yellow instead of red. My rule:
- Green — ship features, sleep well
- Yellow — investigate this week, not at 3am
- Red — wake someone up
The yellow state has saved me from both false urgency (paging for a slow response) and silent decay (a service getting slower every week until it times out).
Why validate the OpenAPI spec inside the monitoring
Step 3 doesn’t just check that /docs-json returns 200. It verifies that three specific paths exist in the spec: /auth/login, /projects, /episodes.
This catches a specific class of bug: someone refactors a controller, renames a route, and the endpoint vanishes from the API. The tests pass because the test suite doesn’t hit that exact path. The frontend works because it hasn’t been updated to use the new route yet. But the spec no longer matches reality.
Checking the spec inside the monitoring means I’m validating the contract that external consumers depend on, not just the implementation.
The trade-off: atomicity vs. correlation
If you’ve written tests before, this design should bother you. One test checking five services violates single responsibility. In a test suite, that’s a bug. In monitoring, it’s a deliberate choice — but it comes with a real cost.
If step 1 (API) fails, the test stops. I never learn whether MinIO is healthy or not. I traded independent visibility for causality: I know why things broke, but not what else is also broken.
The honest answer is that neither approach wins alone. I keep both:
- Atomic checks for each service (
api.check.ts,minio.check.ts, etc.) — they run independently, every 12 hours, and they tell me the state of each service regardless of anything else - The MultiStep check as a correlation layer — it runs every hour and tells me whether the stack works as a system, not just as individual pieces
The atomic checks answer “is MinIO up?”. The MultiStep answers “can a user actually use the product?”. Different questions, different tests.
Where it gets interesting: the atomic checks have caught MinIO outages that the MultiStep would have missed (because the API was also down that day, so the test stopped at step 1). And the MultiStep has caught cascading slowdowns that five green atomic checks would have hidden (each service at 600ms looks fine individually — five of them in sequence taking 3 seconds total is a problem).
If I were starting over, I’d also add per-step response time thresholds instead of a single global one. The API should respond faster than the Swagger endpoint, and MinIO has different latency expectations than the web UI. A flat 800ms for everything is a compromise I haven’t gotten around to fixing.